La web siendo devorada por la IA, un ciclo sin simbiosis
Es el pez que se muerde la cola, la IA necesita información para entrenarse, para dar contenido y respuestas. La web sin visitas no es nada, y ahora mismo los crawlers de las IA no dejan nada a cambio de «llevarse» esa información de las webs, ni siquiera una visita.
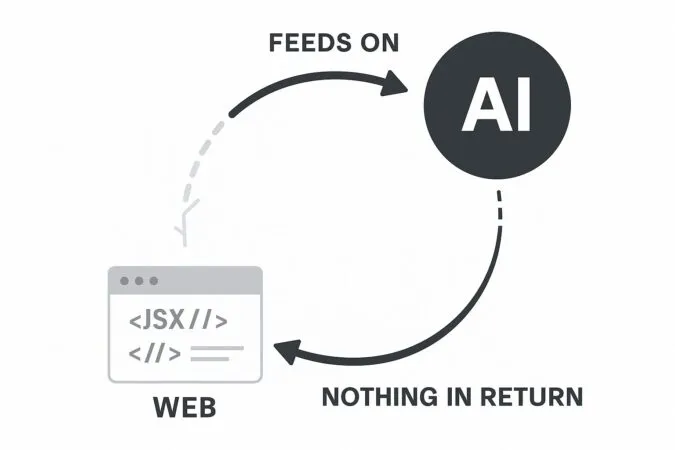
Cloudflare declara la guerra al saqueo de contenido
El 1 de julio de 2025, Cloudflare lanzó un órdago con nombre de revolución: Content Independence Day. El mensaje es claro y directo: los bots de inteligencia artificial ya no son bienvenidos si vienen a servirse sin permiso… ni pagar.
Durante años, modelos como los de OpenAI, Anthropic o Perplexity han vaciado millones de páginas web para entrenarse. Han copiado contenido sin pedir permiso, sin dejar rastro de tráfico, y por supuesto, sin compensar a nadie. El clásico pacto implícito -“yo te indexo y tú ganas visibilidad”- ha sido sustituido por un “me lo llevo todo, gracias y adiós”.

Cloudflare ha venido en plan superhéroe justiciero para decir basta. Y ha movido ficha: a partir de ahora, todos los bots de IA quedan bloqueados por defecto en los sitios nuevos protegidos por su infraestructura, salvo que el administrador decida lo contrario.
Un rastreo sin retorno
Según datos propios de Cloudflare:
- Los bots de OpenAI realizan hasta 1.700 veces más solicitudes que el tráfico real que generan.
- En el caso de Anthropic, la proporción se dispara a 73.000 a 1.
- Solo en marzo de 2025, se registraron más de 26 millones de solicitudes que ignoraron el archivo robots.txt.
Y lo más preocupante: muchos de estos bots ni siquiera se identifican correctamente. Usan user agents falsos o se camuflan tras proxys. Por eso Cloudflare ha activado su sistema AI Labyrinth, un honeypot que redirige a estos bots a un laberinto de páginas falsas donde se pierden, consumen recursos y no llegan a tocar el contenido real.
¿Por qué robots.txt ya no sirve?
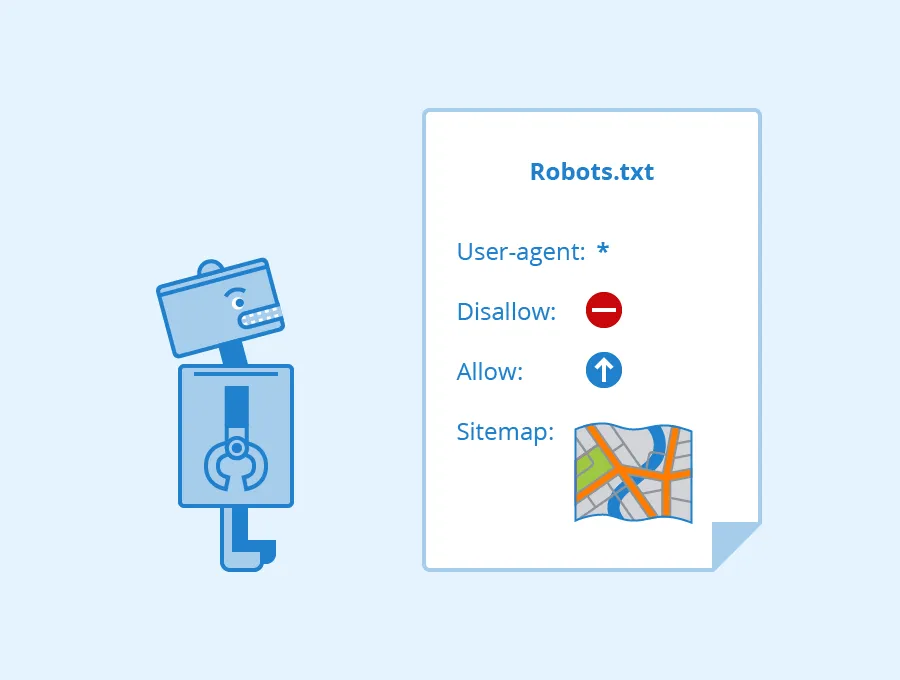
El archivo robots.txt, inventado en los 90, era una solución simple y elegante para una web más inocente. Indicaba a los bots qué podían o no rastrear… con la esperanza de que obedecieran.
Pero hoy, en plena carrera armamentística por entrenar IA más grandes y más rápidas, muchos bots:
- Ignoran robots.txt.
- Lo interpretan de forma creativa.
- O directamente lo desprecian.
La realidad es que no tiene fuerza legal ni técnica. Es una recomendación. No una barrera. Por eso Cloudflare opta por un enfoque más robusto: fingerprinting, análisis de patrones de comportamiento, y bloqueo activo.
Del bloqueo al modelo de pago
El bloqueo es solo el principio. Cloudflare ha recuperado un código HTTP olvidado: 402 Payment Required. Un estándar nunca utilizado… hasta ahora.
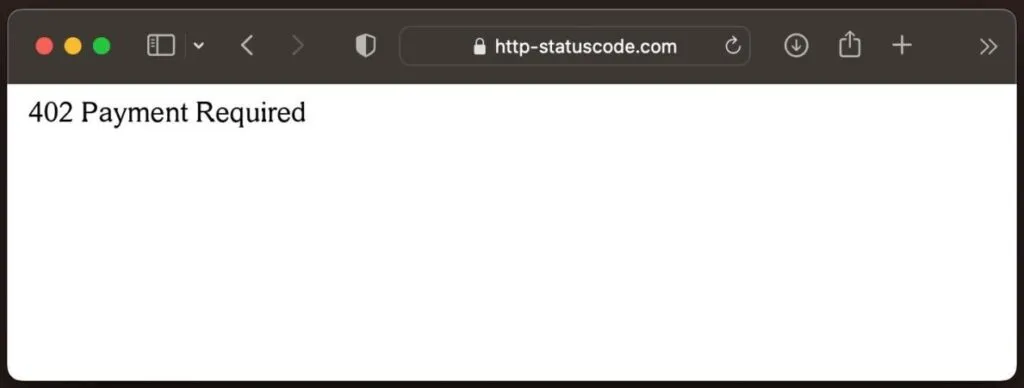
Con su nuevo sistema experimental “Pay Per Crawl”, los bots de IA podrán seguir rastreando contenido, pero tendrán que pagar por cada solicitud. Cloudflare actuaría como intermediario de pagos (merchant of record), garantizando que el creador del contenido reciba una compensación directa.
Este enfoque convierte el entrenamiento masivo de modelos en lo que debería haber sido desde el principio: una transacción económica real, no un saqueo camuflado de progreso tecnológico.
Medios que ya han dicho “basta”
Cloudflare no está solo. Grandes nombres del contenido como:
- Condé Nast (The New Yorker, Vogue),
- The Atlantic,
- Stack Overflow,
- Vox Media,
…han cerrado el grifo a los bots de IA. No se trata de estar “en contra de la inteligencia artificial”. Se trata de exigir una relación más justa y equilibrada entre quienes crean contenido y quienes se benefician de él.
Como dijo el periodista John Battelle, veterano del sector y cofundador de Wired:
“No más rascar sin pagar.”
¿Y el SEO? ¿Esto afecta a mi visibilidad?
Buena pregunta. Y lógica.
El bloqueo no afecta a Googlebot ni a los motores de búsqueda tradicionales que cumplen con las reglas. Cloudflare permite gestionar el acceso bot a bot. Puedes decidir con precisión qué crawler entra, cuál paga, y cuál se queda fuera.
Además, Cloudflare no bloquea el tráfico humano. Solo apunta a los rastreadores que consumen sin aportar. Así que tu estrategia SEO, tu posicionamiento y tu visibilidad en Google no deberían verse afectados.

Una reflexión más personal
Cada vez que publico algo, sé que hay modelos de IA que probablemente lo indexarán, analizarán o reformularán… sin que nadie me lo diga, y sin que yo haya dado consentimiento.
Y no se trata solo de proteger al autor o la autoría en sí: se trata de sostenibilidad. Si el conocimiento libre se convierte en materia prima gratuita para modelos cerrados y privativos, estamos alimentando a bestias que acabarán por hacernos irrelevantes.
¿Estamos ante una nueva economía del contenido?
Para Battelle y muchos otros, esto no va solo de tecnología. Va de repensar los incentivos económicos de Internet.
Durante años, los creadores hemos aceptado el modelo publicitario, el SEO, los enlaces, el CPM, el CPC y toda esa sopa de letras. Pero ahora llega un nuevo jugador que no enlaza, no muestra banners, no genera visitas… solo extrae.

Cloudflare plantea una alternativa: si quieres usar contenido ajeno para entrenar tu modelo, paga por él.
Es un paso hacia una posible licencia comercial de rastreo. Un sistema donde el contenido no es solo texto en una URL, sino valor medible y negociable.
Una visión a futuro: ¿hacia dónde va esto?
Si esta dinámica se extiende, podríamos ver en los próximos años:
- Un sistema de licencias tipo suscripción para IA, algo asi como Spotify, donde los modelos pagan según consumo.
- Creadores y medios usando herramientas como Cloudflare o DRM inteligente para proteger sus webs.
- Legislación europea (DMA) y estadounidense empezando a regular el uso del contenido público por parte de modelos comerciales.
- Incluso, un ecosistema de contenido sintético generado por IA, alimentado por IA… y cada vez más alejado del mundo real.
La paradoja es que, si toda la web se protege, las IA ya no tendrán con qué entrenarse. El pez que se muerde la cola.
Conclusión: encendiendo la mecha
Cloudflare ha sido el primero en plantar cara con medidas concretas. ¿Seguirán todos los demás sus pasos? ¿Reaccionarán las IA? No es solo un manifiesto ético, sino una acción técnica real.
Esto puede marcar el inicio de una nueva etapa, donde la creación digital recupere parte del valor que ha estado cediendo, silenciosamente, durante años.
Porque si seguimos alimentando gratis a las bestias, llegará un momento en el que ellas serán las únicas que tengan valor y poder.
Tengo la impresión de que falta una pieza en este sistema para que haya equidad entre el que da información y el que se alimenta de ella, es un principio básico y este primer paso de Cloudflare es muy valiente pero en la dirección correcta.