ChatGPT-5 no ha provocado el efecto que OpenAI esperaba
Bill Gates es famoso (no solo por su pasado) si no también por sus predicciones. Hace dos años Bill Gates avisó en una entrevista dejando muy claro que las mejoras en los modelos de IA como ChatGPT podrían estar llegando a su límite.
Creo que no se equivocaba, el progreso de GPT-3 al 4 no tiene nada que ver con el progreso del 4 al 5.
Ahora, unos días después desde el lanzamiento de GPT-5 sus palabras parecen tomar fuerza y están por todos los medios. Vamos a verlo en profundidad, voy a ser totalmente objetivo e imparcial, en lo bueno y en lo malo.
Presentación y Novedades que trae GPT-5
El 7 de Agosto de 2025 OpenAI presentó GPT-5. ¿Que cambia?
Hablan de un salto de mejora cualitativa en cuanto a razonamiento, velocidad y utilidad en tareas de escritura, código, matemáticas y salud.
El enrutador que unifica todo en un modo «Auto» que elige por ti cual es la mejor opción, esto es un paso muy positivo ya que antes no quedaba claro que o3 era mejor para razonamiento avanzado que 4o, a nivel de usuario no se entendía.
Antiguos modelos como 4o fueron eliminados los usuarios se echaron encima de ellos y retrocedieron dejándolo disponible temporalmente, según Sam Altman «seguirán de cerca el uso que le dan y cuando lo vean conveniente lo retirarán».
A partir de ahora debes detallar en el prompt que piense de manera más profunda, para dejarle claro, por ejemplo, que quieres hacer una búsqueda extendida.
Para los desarrolladores que utilizan la API hay también novedades. Tres tamaños de disponibles: gpt-5, gpt-5-mini, gpt-5-nano y parámetros verbosity y reasoning_effort.
Lanzamiento con quejas
Los usuarios detectaron respuestas con menos razonamiento, y es que durante las primeras 48 – 72 horas Sam Altman reconoció que el enrutador no estaba seleccionando bien el modelo para dar la respuesta más adecuada, haciendo que a ojos del usuario GPT-5 pareciese más «estúpido» que su versión anterior.
Otro tema a destacar es que en algunas respuestas incluía insultos gays, indica wired .
La comunidad esperaba una «revolución» un salto más grande. Teniendo en cuenta como fue la presentación, no me extraña, creo que pusieron las expectativas muy altas, y la realidad es otra.
Benchmarks
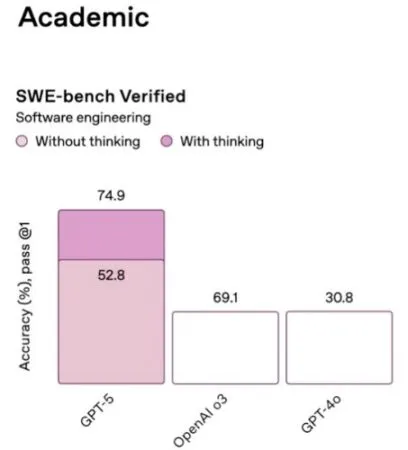
Veis este gráfico que se mostró en la presentación? nadie entiende porque ese valor de 52.8% está por encima del 69.1% de o3 y a la misma vez el 30.8% está al mismo nivel que el 69.1%.
Es un problema a nivel de entendimiento si la presentación tiene como objetivo todos los públicos, desde luego no lo lograron. No es solo una cuestión de entendimiento, han jugado un poco sucio.
De ese benchmark llamado «SWE» eligieron las 477 pruebas que les parecieron mejor, del total de 500, por que? pues porque si esas pruebas eran fallos, el porcentaje bajaría de 74.9% a 71.4% poniéndolo por detrás de Sonnet/Opus. Evidentemente esto contrasta con la realidad y como es lógico, la gente se siente engañada.
El «juego» de los benchmarks cada vez tiene menos sentido.
Al igual que Grok 4, las novedades y los avances de la IA se centran en puntuar mejor respecto a las pruebas y exámenes de inteligencia que se someten para que aparezcan benchmarks mejores, pero la realidad es que cuando haces uso de los modelos de forma cotidiana no lo notas.
Por cierto Elon a dia de hoy presume de que Grok-4 Heavy ya era “más listo” que GPT-5 en un benchmark de Humanity Last Exam.
Reacciones polémicas
OpenAI les ha dado mucho de comer a los trolls de Twitter / X , realmente se lo ha puesto en bandeja y es comprensible que haya salido tanta gente a hablar de esto.
Las opiniones que más he leído son:
- Tiene alucinaciones
- No sigue instrucciones
- Se echa de menos 4o/4.5/o3
- El enrutador falla
- Se busca reducir costes más que empujar el estado del arte
- Excesiva admiración hacia ellos mismos
- De forma general «decepción»
Respuesta positiva, aunque todavía quedan cosas por mejorar
Sam Altman ha estado muy activo en Twitter / X durante el despliegue, y eso es de agradecer. No necesariamente reconoce abiertamente todos los problemas, pero que comunique las extensiones de los límites (doblandolo para usuarios Plus), los modelos antiguos como 4o rehabilitados , o cuando lanzan las opciones de «Auto», «Fast» y «Thinking» es de agradecer.
Sin embargo otras cosas quedaron en el tintero, la ventana de contexto es ahora 32K respecto a los 64K que teníamos con o3.
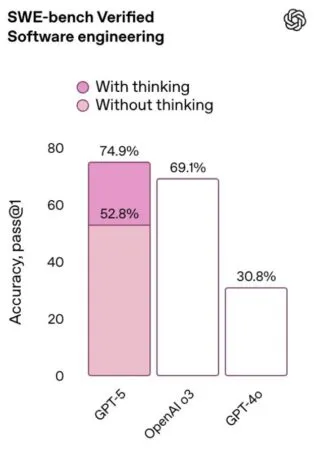
Otro de los miembros que hicieron la presentación se han disculpado en Twitter / X corrigiendo el gráfico que no era coherente:
Poniéndolo a prueba en desarrollo, comparativa con Opus
Es mejor que los modelos de Anthropic? Os cuento mi opinión a nivel personal, lo he estado probando, y siendo sincero, mis pruebas no tienen por que ser conclusivas, simplemente es mi experiencia utilizándolo estos días.
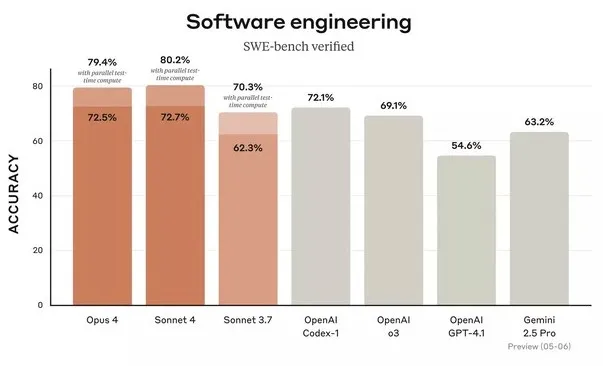
La realidad es que el enrutador todavía no está funcionando muy bien. Funciona mejor que los primeros días, pero aún no atina. Cuando no seleccioné el modo Thinking, se nota claramente que es mucho peor.
El equivalente a Thinking en Anthropic Claude es Opus, y piensa mucho más rápido que GPT-5 Thinking. Tengo además la sensación de que GPT divaga y le cuesta centrarse a la hora de programar. Se pone a pensar y darle vueltas a cosas sin sentido.
En un solo prompt tengo claro que Opus lo hace mejor, sin embargo con más de un prompt y en tareas sencillas, GPT-5 lo hace mejor.
En cuanto a errores, GPT-5 me ha dado más errores, y os digo más, un error que GPT no me solucionaba se lo he pasado a Opus y lo ha solucionado.
Calidad a la hora de entregar funcionalidades – Opus también se lleva este punto a su favor.
En general Opus es el justo vencedor en cuanto a programación.
Impresión personal
He estado usandolo, soy usuario Plus, y sinceramente no noto una diferencia que se pueda percibir respeto a o3 o a 4o. Aún tienen camino por recorrer, no se si esto sea un «estancamiento», tengo muchas ganas de ver lo siguiente de Google con Gemini, al ser modelos de suscripciones la competitividad es muy grande y es fácil pasar de uno a otro, por lo que aquí como usuarios ganamos mucho.
Conclusión
Que todo esto les sirva para mejorar en cuanto a lecciones aprendidas es lo mejor de la crítica constructiva, todo esto lo tienen que transformar en mejorar su producto y hacer mejores despliegues de cara a la próxima versión.